聊聊 PostgreSQL 中的逻辑复制
好几个月前,由于业务需求用到了 PostgreSQL 的逻辑复制(Logical Replication),因此也对这个功能有了一些些的了解。
好几个月前由于业务需求,小小研究了一下 PostgreSQL 的逻辑复制(Logical Replication)。这是一个很有意思的功能,也是一个很容易散发想象力的功能。具体是什么,怎么用,且慢慢看来。
Replication
这个功能要从 PostgreSQL 数据库的流式复制说起。
在 PostgreSQL 9.x 中新增了流式复制的能力,最早是物理复制,创建物理复制槽并且进行主从的同步。在 9.4 版本中又加入了逻辑复制,使得开发者可以通过 WAL 做更多的事情。
一个逻辑复制客户端,可以连接到 PostgreSQL 并且不断接收到数据库记录变动的事件,并且按照自己的代码逻辑进行处理。
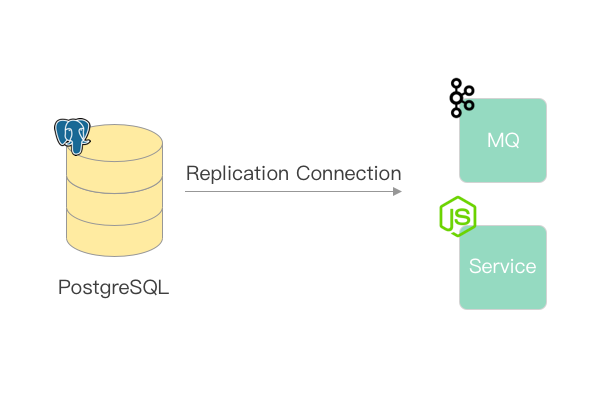
通过逻辑复制,我们可以将数据库的所有变动事件同步到其它地方,如消息队列,或者我们自己实现一个逻辑复制客户端。除了用于数据库备份,甚至可以用它来触发业务操作。
PostgreSQL 的逻辑复制使用了发布订阅的模型,PostgreSQL Master 服务器作为发布者,会将变动的数据发送到所有的「复制槽」对应的进程,也就是逻辑复制客户端中,逻辑复制客户端通过「复制槽」订阅变动的事件,并在 PostgreSQL 中维护自己的进度状态等信息。
模拟从库
使用逻辑复制功能,实际上就是模拟了一个从库,需要做的事情主要是如下几点:
- 建立连接
- 创建复制槽
- 开始监听 WAL 事件
- 定时刷盘
接下来使用 Node.js 实现逻辑复制客户端的功能,通过纯 JS 实现的库——pg 来实现。从相关 Pull Request 来看,在 2017 年该库已经加入了对复制链接的支持。
建立复制连接
首先要做的是创建数据库连接,对于 pg 模块来说,只需要多传入一个 replication: 'database' 参数即可,对于复制连接,pg 仅支持进行一些简单的查询,同时 pg 会拒绝参数化的查询。
1 | import { Client } from 'pg'; |
如果想要同时做一些复杂的查询,可以另外开启一个非复制连接配合做查询、修改等操作,至于为什么是有必要的,后面会讲到。
创建复制槽
这一步是非必要的,如果之前数据库中已经创建了同名的复制槽,并且想继续沿用,那么便可以不创建新的复制槽了,而且对于已有且重名的 slot,再次创建会报错。
创建复制槽有两种方式,一个是通过连接传输指令:
1 | CREATE_REPLICATION_SLOT slot_name [ TEMPORARY ] { PHYSICAL [ RESERVE_WAL ] | LOGICAL output_plugin [ EXPORT_SNAPSHOT | NOEXPORT_SNAPSHOT | USE_SNAPSHOT ] } |
除了连接传输指令,也可以通过 SQL 语句调用创建函数来创建:
1 | SELECT pg_create_logical_replication_slot('slot_name', 'plugin_name'); |
使用第一种方式来创建复制槽的代码如下:
1 | interface CreateReplicationResponse { |
创建时可以指定 Logical Decoding 插件,默认使用内置的 test_decoding 将二进制的 WAL 翻译成 SQL 语句,我在使用的时候使用了 wal2json 插件作为 Decoding,直接将变动转为 JSON 数据,便于程序中进行解析。
开始复制
上一步的创建复制槽会返回一些有用的数据,从定义的返回值结构就可以看到有一个 consistent_point 字段,这个字段是当前 LSN 的位置,解析可以得到准确的 64 位整数的 LSN。
1 | let walPosition = BigInit(0); |
因此首先创建复制槽,并且根据返回的信息初始化我们实现的程序当前的 LSN 位置。然后通过连接传输指令开始复制:
1 | START_REPLICATION SLOT [SLOT_NAME] LOGICAL 0/0 |
这个语句后面可以加一些参数,例如是否返回 xid、timestamp 等。
接下来直接执行生成的命令就可以了。不过执行成功后,这个连接便只能用于接收数据库的变动事件了,无法再用来进行查询。
最后一步创建了一个定时器,每五秒执行一次 updateStandByStatus() 。这个函数便是进行刷盘的动作了。
模拟刷盘
所谓刷盘就是告诉 PostgreSQL 在当前 LSN 之前的变动数据客户端都已经处理妥当了,PostgreSQL 可以放心将 WAL 进行处理了。而且如果长期不进行刷盘,链接也会被 PostgreSQL 主动断开。
在我们自己实现中,这一步骤自然也是必不可少的,刷盘的指令是通过给 PostgreSQL 发送数据来实现的:
1 | function getStandByStatus(walPosition: bigint): Buffer { |
具体的计算逻辑只需要按照 PG 文档在具体的位置进行填充就好了。上面的代码里也标注了文档中的信息。
获取数据
至此,所有的基本骨架已经完成了,只需要监听 PostgreSQL 传来的事件即可。
这在 Node.js 这个事件驱动的世界里再简单不过了:
1 | client.connection.on('copyData', data => { |
其中 copyDataIdentifier 是字母 w 的 ASCII 码,如果收到的数据包的第一个字节为该值,则意味着这是一个变动的数据包;如果第一个字节为 k 则代表这是 PostgreSQL 发来的希望客户端及时响应刷盘心跳的 keepalive 数据包。
至此核心的逻辑都已经实现了,只需要将这些函数组装,或者封装即可。我使用了继承自 EventEmitter 的类来封装,然后对外暴露一个 on('change') 的事件,来注册并且处理。
当然也可以通过结合持久化存储等实现更为复杂的功能。
踩过的坑
不用的 Slot 一定要及时清理。Replication Slot 创建后,意味着 PostgreSQL 需要一直为这个 Slot 保留 WAL,以便在它连接上来后,能够将数据发给客户端。这也是因为 PostgreSQL 中是这样设计的来保证客户端收到的数据的完整性。因此如果 Slot 存在且客户端下线,会造成 WAL 不断积压,直至把硬盘撑满。而且这个情况下 WAL 不受 max_wal_size 参数的控制。
我们可以通过额外的进程,定时检查是否有未激活的复制槽,并且是否已经离当前 LSN 差距过大,如果有的话及时清理掉。通过如下 SQL 可以查到有问题的 Slot:
1 | SELECT redo_lsn, slot_name, restart_lsn, round((redo_lsn-restart_lsn)/1024/1024,2) AS behind FROM pg_control_checkpoint(), pg_replication_slots; |
在 PostgreSQL 13 中,新加入了一个参数 max_slot_wal_keep_size 用于限制由于 Slot 导致的 WAL 无限增长的问题。
按需使用 REPLICA IDENTITY。REPLICA IDENTITY 是数据表的属性,它代表了 WAL 中流式复制过程中,更新与删除操作所记录的数据纬度。这个字段提供了 DEFAULT,FULL,INDEX,NOTHING 几个值。
DEFAULT是默认值,会提供主键等关键信息,如果没有主键的表则不会传输变动。FULL会将整个表的行记录记录并传送,会有较大的数据冗余,在需要的时候设置。INDEX可以设置记录索引列,可以用来进行一些避免冗余的场景。NOTHING则什么也不做。
为 NULL 且不变的字段不会传输。即使是设置数据表的 REPLICA IDENTITY 为 FULL,依然无法接收到未发生变动,且一直为 NULL 的字段,这里处理需要小心,避免用 NULL 值覆盖了原值。
小结
逻辑复制的功能可以有很广泛的用途,我在业务中主要是用来监听数据变化,并用于触发其他的业务操作,具体能做到的事情肯定有很多,可以根据自己需要的场景来选择是否使用。
除了直接在程序中对接,也可以通过中间件直接对接到 Kafka 中,来提升整个系统的健壮性和分布式的能力。